


by Striped Giraffe Team
6. June 2019
Reading time: 11 Minutes
Lightweight Machine Learning and Analytics
Writing yet another article on machine learning is like adding a drop of water to the ocean. Machine learning is one of the hottest topics in IT right now, and it is here to stay… or isn’t it?
Beyond the hype
IT is driven by hype cycles. Valid technical breakthroughs often go mainstream and become extremely popular. This is usually followed by a period of declining popularity and disillusionment, sometimes then followed by enlightenment and low-profile commercial adaptation. Two recent buzzwords—cloud computing and big data—are examples of hot topics that have been through this kind of popularity peak.
Figure 1. Interest in big data, machine learning and cloud computing in the recent years
Of course, cloud computing and big data technologies like Hadoop remain credible solutions, but they are now approached with more reserve and caution than they used to be.
So will AI follow the same path? Actually, it already had. Hard artificial intelligence (machines able to replicate or exceed human cognitive abilities) has been thought to be just around the corner ever since the dawn of the digital era. The first hype cycle started in the 50s with the emergence of algorithms like basic neural networks and rule-based classifiers. The general expectation was that these solutions would quickly lead to human-level intelligence. Obviously that wasn’t the case in that decade and an investment freeze followed. However, machine learning was developed continuously throughout 80s, 90s and 2000s. Many critical shallow learning algorithms like support vector machines, random forests and data clustering techniques were developed in this period. Ironically, many researchers working in this area avoided the term artificial intelligence, so as not to be considered the daydreamers of earlier periods.
Machine learning’s current popularity was triggered by the successes of deep neural networks in challenges that earlier shallow learning algorithms could not handle. These challenges are mostly tasks related to image, video, speech or text analysis, which can be considered unstructured big data. Indeed, many accomplishments in this field are impressive and might provide an illusion of near human level intelligence.

By loading the video, you agree to YouTube's privacy policy.
Learn more
YOLO (You Only Look Once) — real-time object detection system
Machine learning is a powerful tool, but despite all the enthusiasm it is important to remember potential project challenges. Some of these are listed below.
Inherent challenges
Data fragmentation
Obviously a machine cannot learn—whether it be prediction, clustering or pattern detection—without input data. Machine learning models usually require a precise description of the task. It is not possible (in 2019) to just unleash an AI algorithm on the entirety of a company’s fragmented data assets without precise requirements. For example, in order to train a prediction model pertaining to customers, all the data that might be relevant for the model (e.g. products bought, images of purchased products, customer comments, sales statistics, address etc.) has to be brought together in a single system. If the model is not only supposed to be a proof of concept exercise, permanent data integration processes have to be constructed.
Data discovery
Very often it is not clear what data is available in the company and how the various data sources are related to each other. Data discovery is a process that needs to take place even before data integration. Needless to say, the data landscape is evolving all the time, so this effort has to be regularly repeated.
Data quality
Machine learning models are often susceptible to very minor disturbances in the data. A sheet of paper presumably sold for €100,000 is an example of such a disturbance. Records like this need to be dealt with either by simple data removal, or in more advanced scenarios by data correction.
Data completeness
Machine learning is not magic, it just uncovers relationships in the collected data. So what if no relationships can be found? That means that either not enough data has been collected, or that the relationships do not exist. Either way, the models would not provide a satisfactory performance.
Data freshness
It is not enough to train a machine learning model once. Models need to be constantly retrained with new data so that they remain up-to-date. And what if the model strongly impacts customer behavior, which becomes its own future input data? This creates additional feedback loops that might need to be considered.
The issues raised so far are results of the nature of problems, tools and techniques available. Alongside them, there is also a group of disturbances that are caused by the machine learning hype itself.
Fear of missing out
Fear is rarely a good advisor, especially when it comes to long-term decision making. Fear of missing the next IT revolution can cause decision-makers to follow risky paths, or even to neglect core business processes in favor of more progressive, but not necessarily profitable initiatives.
Risk of overinvestment
Each project costs money. Machine learning and analytical projects are mostly about uncovering unknown relationships or automating a decision-making process based on collected data and human-provided learning vectors. In either case, it is often not known at the beginning of the analysis if the relationships indeed exist, how strong they are, and how difficult it would be to find them. This makes it very hard to predict if the investment returns would be worth it.
Fixation on deep learning
For many people, machine learning and deep learning through neural networks are synonymous. In reality, neural networks are just one possible family of models. Ironically, neural networks are one of the least “learning” of all the model types, as they use fixed network architectures. Different problems call for different network architectures, and the whole network design process is often driven by human intuition.
Neural networks need to be engineered before they can be trained. Many shallow learning algorithms like random forests or gradient boosting offer more accurate predictions for mixed numerical-categorical datasets. At the same time, they are orders of magnitude less computationally expensive to train. In contrast to neural networks whose structure needs to be defined prior to training, the structure of these shallow learning models is created automatically during the learning process.
Different problems call for different models. Using neural networks for all the tasks just because they are popular is a way to slow down a project and make it more expensive.
Win or die attitude
Many data science practitioners want to use machine learning as a career booster. This makes them more than eager to put a machine learning related project in their CV. They might be interested in pursuing an unfeasible project, in the belief that it might kick-off their machine learning portfolio. This bias is something that should be considered by project stakeholders. Risk is acceptable, as long as it is controlled and clearly stated.
Skill ambiguity
The final problem we discuss here is skill ambiguity. In well-established areas of IT, it is relatively clear what makes the difference between a senior engineer and junior engineer, and what makes the difference between a competent and incompetent specialist. Furthermore, certificates – while obviously not being enough to assess someone’s skills – provide valuable indications. When it comes to progressive areas like machine learning, however, it is not that clear yet, as one year’s breakthrough is often another year’s dead end.
Lightweight projects
The points raised above are by no means designed to discourage anyone from doing machine learning projects. They are just a list of things to be considered when planning such initiatives. But what if you want to do machine learning and advanced analytics activities without overly risky investments? There is a whole range of robust, lightweight projects that can be performed with minimal commitment.
Time series forecasting
A time series forecast is a very simple type of model. In contrast to deep learning models operating on tens of thousands of pixels, and even to shallow learners working on hundreds of table columns, most forecasts use only one variable. More specifically they use the history of values of that variable to predict its future. Practically, this could mean sales or revenue forecasting. One commonly used model is ARIMA – Autoregressive Integrated Moving Average. This type of model operates on differences of values at different points in time, and makes predictions based on those differences and its own prediction errors. Normally, the number of autoregressive and moving-average components needs to be explicitly provided by an analyst. Luckily, R’s package forecast allows these parameters to be tuned automatically. An R session can connect to most relational databases using ODBC or JDBC drivers via RODBC and RJDBC packages. Microsoft SQL Server users can seamlessly integrate R code with T-SQL stored procedures using SQL Server Machine Learning Services.
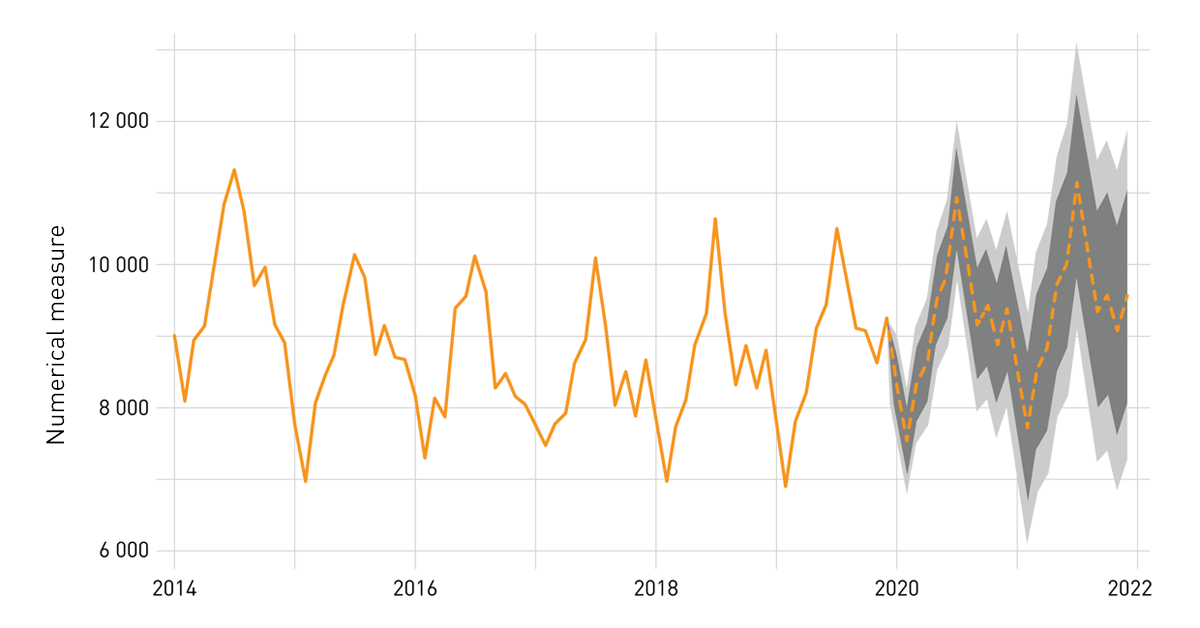
Figure 2. A sample forecast
Useful R packages:
- https://cran.r-project.org/web/packages/forecast/index.html
- https://cran.r-project.org/web/packages/RODBC/index.html
- https://cran.r-project.org/web/packages/RJDBC/index.html
SQL Server Machine Learning Services homepage:
Forecasts provide an intuitive summary of expected values of numerical measures such as sales and revenue, and can be displayed alongside historical data. With some effort, they can be calculated automatically for multiple combinations of aggregations such as products and customer segments. While the trends and seasonality cycles of total sales and revenue are most likely known to the sales teams, viewing them for different products or different groups of customers can provide useful insights.
Customer and product proximity measures
Customers and products have various individual properties. For example, a customer might have age and address properties and a product might have a picture and list-price tag. There are some additional properties shared between these two entities, like a product rating or product comment made by a specific customer. The availability and quality of these features can vary across companies. However, almost every company has invoice data – the amount of money each customer spends on each product. This data can be aggregated into a PRODUCT—CUSTOMER matrix, possibly after filtering to most recent purchases.

Figure 3. Product—Customer sales matrix
Rows and columns of this matrix can be analyzed using techniques as simple as correlation. Positive correlation between products can be interpreted as a measure of complementarity (hammer and nails), while negative correlation can be interpreted as competition (Pepsi and Coca-Cola). It is also possible to analyze correlations between customers. This can be accomplished using basic analytical tools such as R and Python or even SQL alone.
Market basket analysis
Market basket analysis is one of the most heavily used and cited types of analytics. While usually run on the entirety of data, it can be also performed individually for each customer. This can be used to create personalized basket templates, which a customer can pick up and customize when shopping. As before, this can be accomplished with relatively little effort and in a predictable time using R or Python packages and relational database integration.
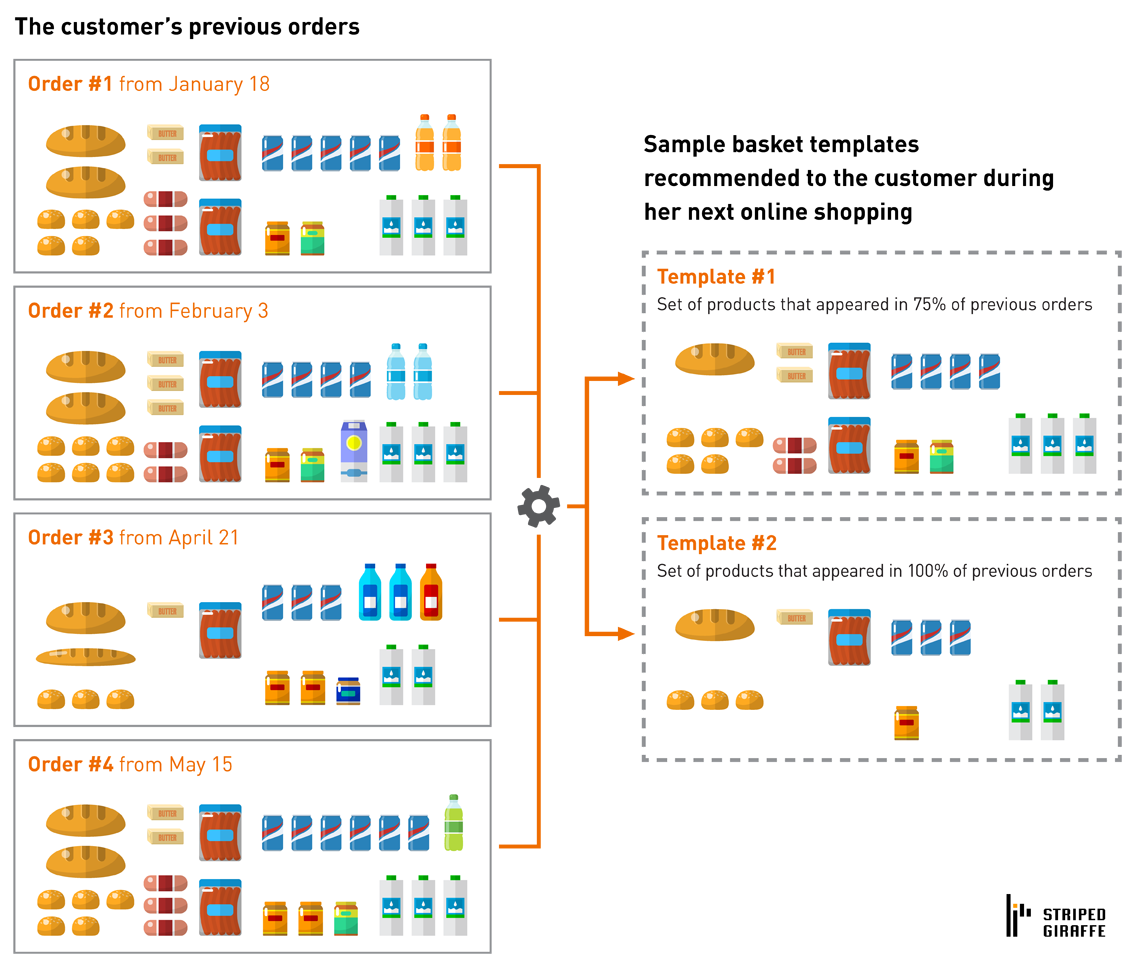
Figure 4. Market basket analysis (oversimplified)
A more straightforward approach is to ignore the quantities of purchased products, and just provide 1 unit for each product present in the basket template.
Summary
Deep learning initiatives may require substantial investments and their feasibility is often difficult to assess at the beginning of the project. “Lightweight” analytical techniques like those presented are a robust alternative with predictable budget. Furthermore, they can be used to create a sustainable analytical culture in the company, thus helping to stay in the machine learning business after the hype is gone.
